Amazon DynamoDB is a fully managed NoSQL database service that provides fast and predictable performance with seamless scalability. You can use Amazon DynamoDB to create a database table that can store and retrieve any amount of data, and serve any level of request traffic. Amazon DynamoDB automatically spreads the data and traffic for the table over a sufficient number of servers to handle the request capacity specified by the customer and the amount of data stored, while maintaining consistent and fast performance.

AWS DynamoDB stores data on Solid State Drives (SSDs) and replicates it synchronously across multiple AWS Availability Zones in an AWS Region to provide built-in high availability and data durability.
AWS DynamoDB eases developers’ challenges of provisioning hardware and software, including setting up and configuring a distributed database cluster and managing ongoing cluster operations.
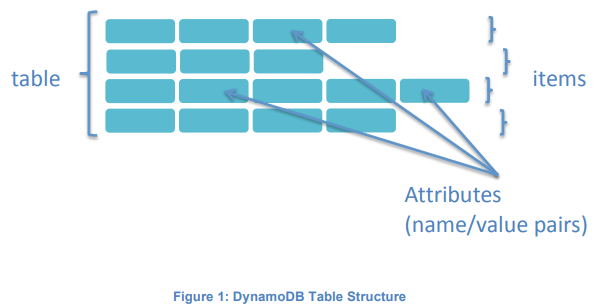
Tables are the fundamental construct for organizing and storing data in DynamoDB.Each table should have one attribute as primary key. And every table is indexed by the primary key.
Each item in the table can be expressed as a tuple containing an arbitrary number of elements, up to a maximum size of 400K.
The connections to Amazon DynamoDB are http(s) based.
DynamoDB - Index
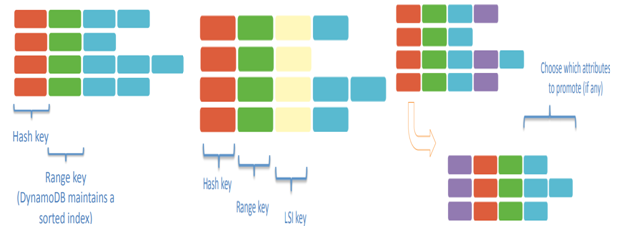
A local secondary index uses the same hash key as defined on the table, but a different attribute as the range key. A global secondary index can use any scalar attribute as the hash or range key. In addition, global secondary indexes require that attribute values be projected into the index. What this means is that when an index is created, a subset of attributes from the parent table need to be selected for inclusion into the index. When an item is queried using a global secondary index, the only attributes that will be populated in the returned item are those that have been projected into the index. Original hash and range key attributes are automatically promoted in the global secondary index
A read unit consists of 4K of data, and a write unit is 1K.
If no index exists on the column used to fetch the data, a full table scan may be required to locate the matching rows.
DynamoDB does not support the concept of a table join.
DynamoDB – Features
DynamoDB supports following data types:
Scalar – Number, String, Binary, Boolean, and Null.
Multi-valued – String Set, Number Set, and Binary Set.
Document – List and Map.
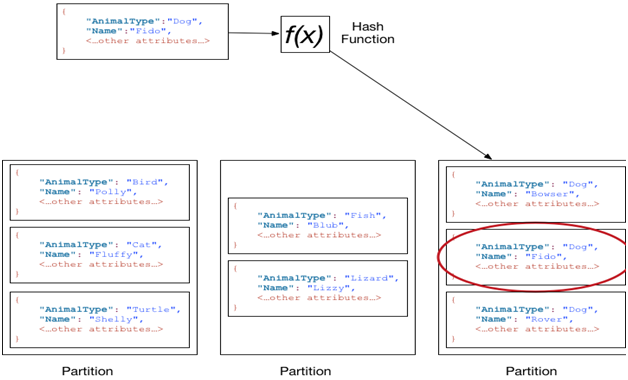
Query DynamoDB must by hash key to decide in which partition and further filter by range key in current partition. So based on Hash Key, you only can be query equal, instead of less, great or begin with, more flexible way can be only used in range Key.
DynamoDB – Partitions
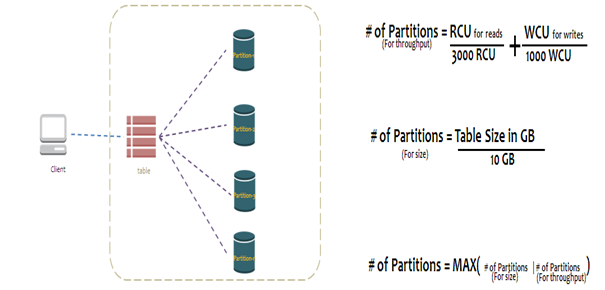
The partitioning logic depends upon two things: table size and throughput.
According to this formula, if we have a table size of 16 GB and we have 6000 RCUs and 1000 WCUs, then:
# of partitions by throughput: 6000/3000+1000/1000 = 3
# of partitions by size: 16/10 = 1.6
So, the # of partitions in total: max(1.6, 3) = 3
Consistent hashing is a special kind of hashing such that when a hash table is resized and consistent hashing is used, only K/n keys need to be remapped on average, where K is the number of keys, and n is the number of slots. In contrast, in most traditional hash tables, a change in the number of array slots causes nearly all keys to be remapped because the mapping between the keys and the slots is defined by a modular operation.

Consistent hashing is based on mapping each object to a point on the edge of a circle. The system maps each available storage node to many pseudo-randomly distributed points on the edge of the same circle. To find where an object O should be placed, the system finds the location of that object’s key on the edge of the circle; then walks around the circle until falling into the first bucket it encounters. The result is that each bucket contains all the resources located between its point and the previous bucket point. If a bucket becomes unavailable (for example because the computer it resides on is not reachable), then the angles it maps to will be removed. Requests for resources that would have mapped to each of those points now map to the next highest point. Since each bucket is associated with many pseudo-randomly distributed points, the resources that were held by that bucket will now map to many different buckets. The items that mapped to the lost bucket must be redistributed among the remaining ones, but values mapping to other buckets will still do so and do not need to be moved. A similar process occurs when a bucket is added.
The basic implementation of consistent hashing has its limitations:
Random position assignment of each node leads to non-uniform data and load distribution.
Heterogeneity of the nodes is not taken into account.
To overcome these challenges, DynamoDB uses the concept of virtual nodes. A virtual node looks like a single data storage node but each node is responsible for more than one virtual node. The number of virtual nodes that a single node is responsible for depends on its processing capacity.
Replication in DynamoDB
Every data item is replicated at N nodes (and NOT virtual nodes). Each key is assigned to a coordinator node, which is responsible for READ and WRITEoperation of that particular key. The job of this coordinator node is to ensure that every data item that falls in its range is stored locally and replicated to N - 1 nodes. The list of nodes responsible for storing a certain key is called preference list. To account for node failures, preference list usually contains more than N nodes. In the case of DynamoDB, the default replication factor is 3.
Reference:
https://d0.awsstatic.com/whitepapers/migration-best-practices-rdbms-to-dynamodb.pdf
https://cloudacademy.com/blog/dynamodb-replication-and-partitioning-part-4/